Удалить все html-теги Notepad++

Чистка Html-кода с помощью редактора Notepad++
1) Обычная замена - букв, слов, словосочетаний.
Тут без открытий – жмём Ctrl+H (или через меню Search->Replace) - появляется стандартное окно.
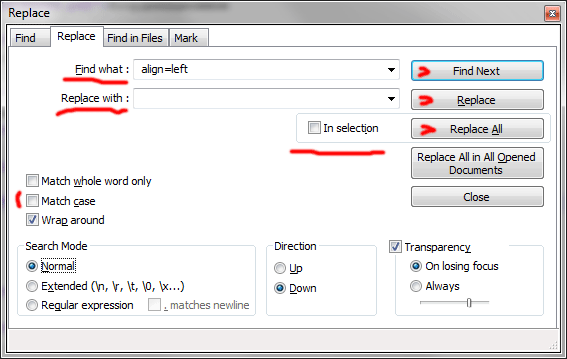
Вводим ‘align=left’ (без кавычек) в поле Find what:, убеждаемся, что в поле Replace with: пусто и смело жмём кнопку Replace All.
Все входы align=left в тексте будут изничтожены. Если галочка различия регистра букв Match case не взведена (по умолчанию именно так), то прибьются все написания, типа align=LEFT и т.п.
Если кусок текста в редакторе был выделен, можно взвести галку In selection, и замена произойдёт только в рамках выделенного текста.
Если вначале хочется посмотреть, что именно будет заменено, можно понажимать кнопки Find Next и Replace для пошагового поиска-замены.
Для "особо продвинутых пользователей" есть кнопка Replace All in All Opened Documents – чтобы осуществить замену во всех открытых Notepad++ файлах (во всех закладках редактора). Такое я себе позволяю только при многократной замене двух пробелов на один.
2) Расширенные возможности замены. Спецсимволы.
Что делать, если есть необходимость заменять какие-либо спецсимволы?
Для этого снова нажимаем Ctrl+H и в знакомом нам окне переключаем режим замены на Extended.
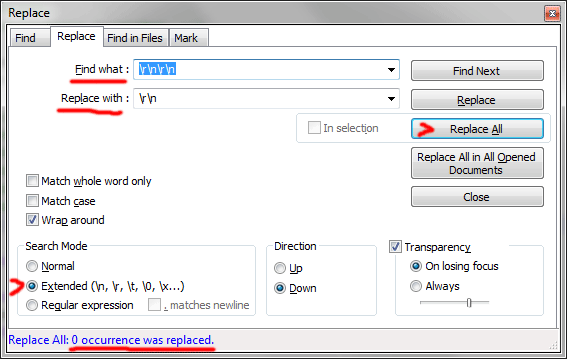
Теперь мы можем удалять из текста, к примеру, пустые строки.
Каждая обычная строка заканчивается парой исторических символов – конец строки + перевод каретки.
Они записываются как ‘\r\n’ (без кавычек).
Для того, чтобы удалить из текста все пустые строки надо несколько раз заменить по всему тексту ‘\r\n\r\n’ на ‘\r\n’ тупо нажимая кнопку Replace All пока в файле есть что менять.
Можно также понажимать кнопки Find Next и Replace для пошагового поиска-замены.
3) Замена с помощью регулярных выражений.
На том же экране поиска-замены есть третья опция в Search Mode – Regular expression.
И в этом режиме можно легко делать феноменальные вещи!
А) Удаляем из файла все HTML-тэги. Вводим в строку поиска <[^>]*> и жмём Replace All.
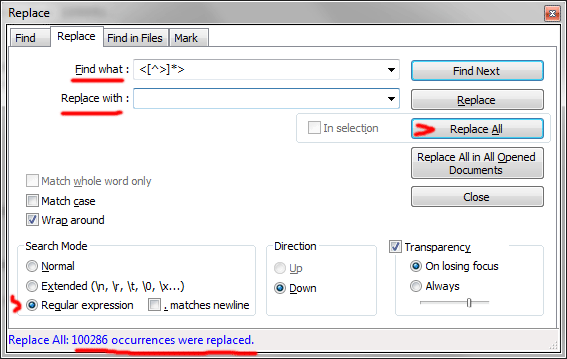
Результат – получили чистый текст.
Б) Удаляем из текста все HTML-комментарии. Вводим в строку поиска <!--([\s\S]*?)--> и жмём Replace All.
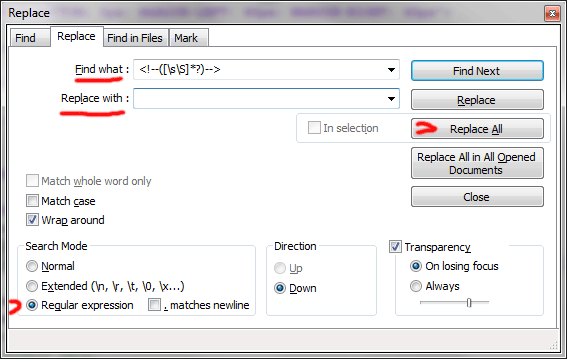
Удалились все комментарии. Причём, как и в первом случае, даже многострочные, чего при построчном импорте в DBF или Excel и последующей программной обработке - очень трудно добиться.
В) По аналогии, так можно удалять, к примеру, ASP-код с помощью такого регулярного выражения: <%([\s\S]*?)%>
Г) Особо хорошо с помощью регулярных выражений чистить изгаженный Вордом HTML-текст.
Вначале можно заменить <p class=MsoNormal([\s\S]*?)> на <p>
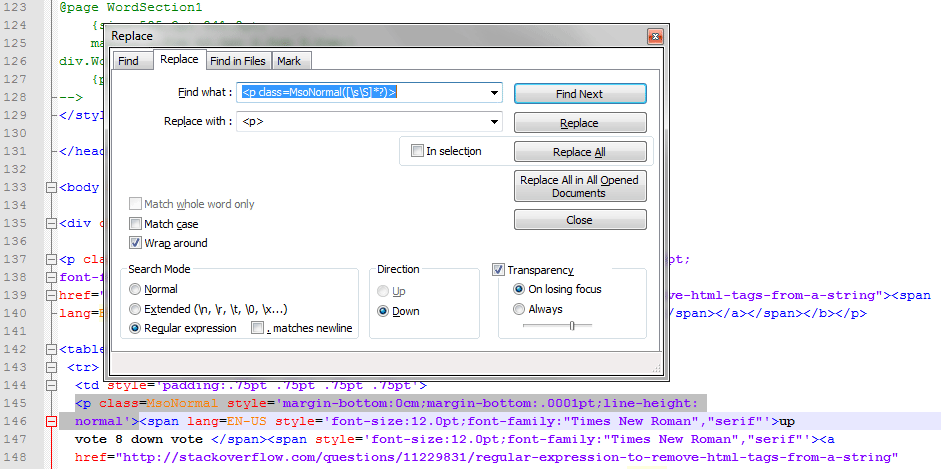
А затем в два приёма ликвидировать все спаны.
Вначале меняем <span([\s\S]*?) на <span>:
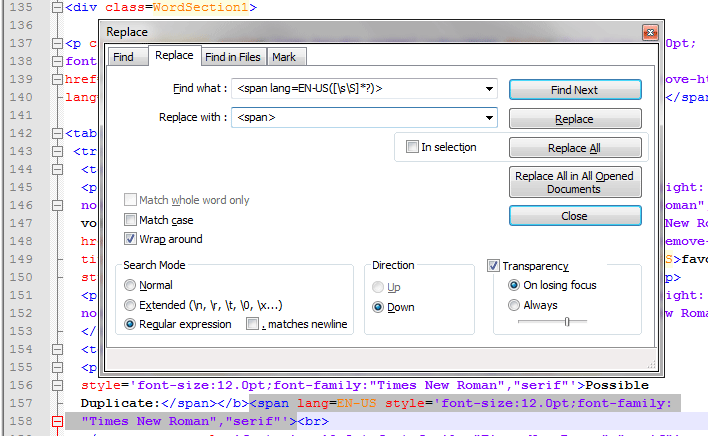
А потом удаляем в обычном режиме и <span>, и </span>.
0 комментариев